MLOps, LLMOps, and AgentOps: The New Operational Stack for AI
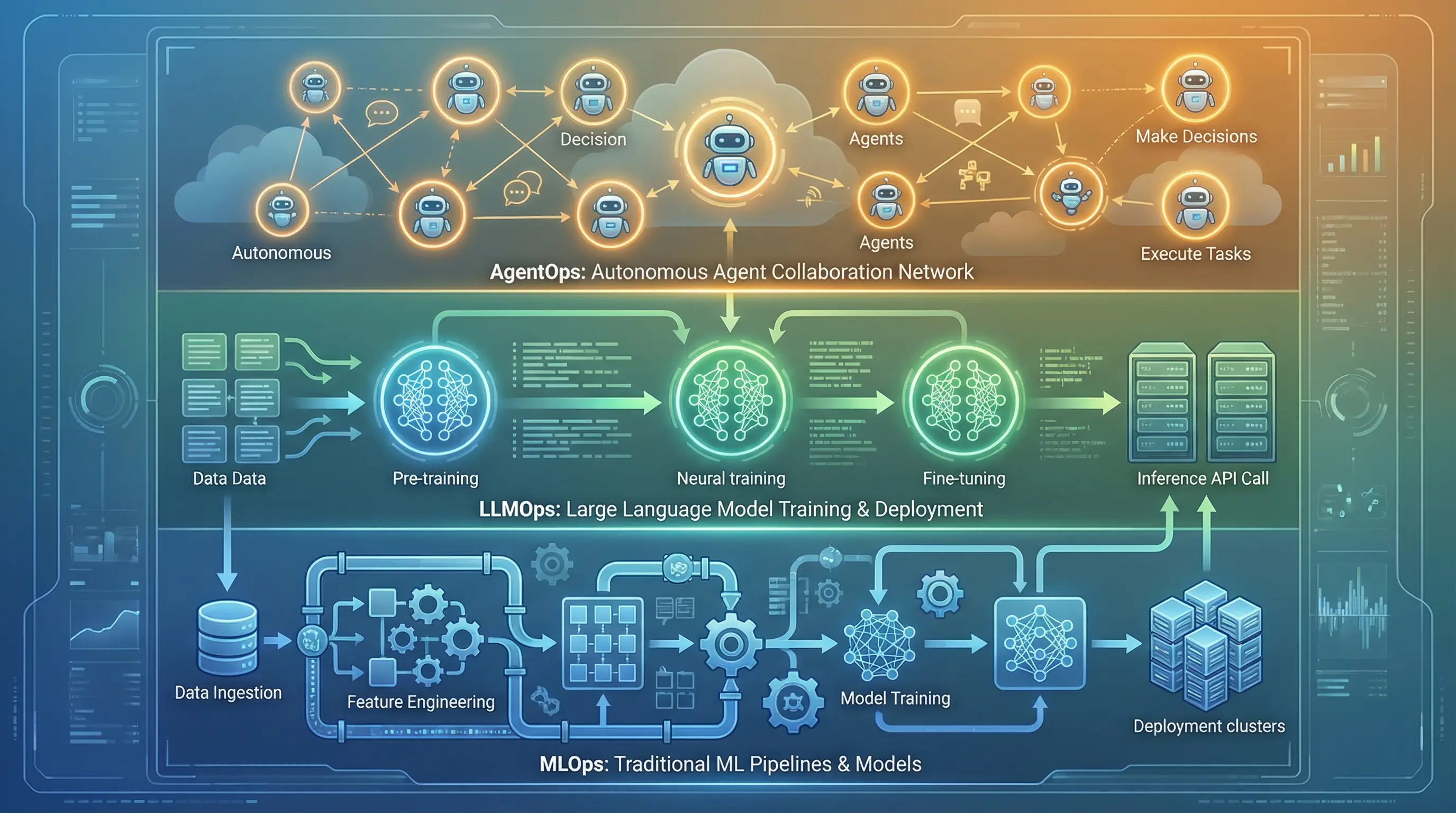
The AI landscape has changed dramatically over the past decade. What started as isolated ML experiments in Jupyter notebooks has turned into production systems that need real operational discipline. As AI systems have grown more complex—from traditional ML models to large language models and now autonomous agents—the practices for managing them have had to evolve too.
This evolution has produced three distinct operational frameworks: MLOps, LLMOps, and AgentOps. Each one tackles different challenges in deploying and maintaining different types of AI systems. Understanding when to use each framework matters if you’re trying to run AI in production.
The Evolution of AI Operations
The shift from MLOps to AgentOps isn’t just about incremental improvements. It’s about how AI systems have fundamentally changed in what they do and how they behave.
MLOps emerged to solve the “last mile” problem of machine learning—getting models from notebooks into production. It brought DevOps principles to ML: version control, automated testing, continuous deployment.
LLMOps came next because large language models broke traditional MLOps assumptions. The scale of LLMs, their dependence on prompt engineering, and their token-based pricing model needed different operational practices.
AgentOps is the newest addition, built for autonomous agents that can make decisions, chain tasks together, and interact with their environments. Unlike static models, agents behave non-deterministically. You can’t just monitor their inputs and outputs—you need to understand their reasoning process.
MLOps: The Foundation of AI Operations
MLOps is where modern AI operations started. It covers the complete lifecycle of machine learning models—from data preparation through deployment and monitoring. Everything that came after builds on these practices.
Core Components of MLOps
Data engineering and management is the backbone of any ML system. You build automated data pipelines using tools like Apache Airflow and Apache Spark to handle extraction, transformation, and loading. Data versioning tools like DVC let teams track dataset changes across experiments. Data quality monitoring through frameworks like TensorFlow Extended catches anomalies, missing values, or distribution shifts before they tank your model’s performance.
Model experimentation and versioning lets data scientists systematically explore different approaches. Experiment tracking platforms like MLflow and Weights & Biases log hyperparameters, metrics, and configurations. Model registries document metadata, training data, and performance metrics—basically an audit trail for every model version.
Deployment and CI/CD adds software engineering discipline to ML. Automated pipelines using Jenkins or GitLab CI/CD test models thoroughly before deployment. Containerization with Docker and orchestration using Kubernetes give you flexible, scalable deployments.
Monitoring and maintenance keeps models performing well in production. Tools like Prometheus and Grafana track metrics like accuracy, latency, and throughput. Specialized monitoring solutions like NannyML and Evidently AI detect data drift and concept drift, which tells you when models need retraining.
When to Use MLOps
MLOps works well for traditional machine learning models with well-defined inputs and outputs:
- Predictive maintenance systems in manufacturing that forecast equipment failures
- Fraud detection models in finance that analyze transaction patterns
- Recommendation engines in retail that personalize customer experiences
- Computer vision applications for quality control or object detection
- Time series forecasting for demand planning or resource allocation
These models are task-specific, trained on structured or semi-structured data, and produce deterministic outputs for given inputs.
LLMOps: Scaling Language Models
Large language models broke traditional MLOps in several ways. The scale of these models, their dependence on prompt engineering, and their unique cost structures needed a different operational approach.
The LLMOps Difference
Foundation model selection replaces traditional model training. Few organizations can afford to train foundation models from scratch—a 2020 study estimated training GPT-3 would cost $4.6 million and take 355 years on a single Tesla V100 instance. Instead, teams pick between proprietary models (GPT-4, Claude) and open-source alternatives (LLaMA, Flan-T5), weighing performance against cost and flexibility.
Prompt engineering becomes a core discipline. Unlike traditional ML where model architecture drives performance, LLMs need carefully crafted prompts to produce the right outputs. Tools like PromptLayer let you iteratively test and optimize prompts. “Programming” an LLM often means natural language engineering rather than writing code.
Resource optimization tackles the computational demands of LLMs. Techniques like model distillation and quantization shrink model size without killing performance. Serverless architectures and distributed frameworks enable cost-effective deployment. The cost model flips from training-heavy (MLOps) to inference-heavy, with token-based pricing making prompt length and output size direct cost factors.
Fine-tuning and domain adaptation let teams specialize general-purpose models. Transfer learning and parameter-efficient techniques like Low-Rank Adaptation (LoRA) enable customization without the full computational cost of training from scratch. This matters for domain-specific applications in healthcare, legal services, or technical support.
Ethics and content moderation become more important. LLMs can generate biased, harmful, or inappropriate content. LLMOps includes bias detection tools, content filtering APIs, and human-in-the-loop feedback to keep outputs within ethical and regulatory boundaries.
Challenges in LLMOps
Hallucination management is one of the biggest problems. LLMs confidently generate false information, so validation and fact-checking are essential. Retrieval-Augmented Generation (RAG) pipelines help by grounding responses in verified data sources, which reduces hallucination rates.
I’ve seen production systems where an LLM confidently cited non-existent research papers in customer-facing documentation. The papers sounded plausible—complete with realistic author names and publication dates—but they didn’t exist. RAG helps by forcing the model to pull from verified sources, but you still need human review for high-stakes content.
Cost optimization needs constant attention. With token-based pricing, every prompt and response costs money. Teams balance model selection (larger models are more capable but expensive), prompt length, output constraints, and caching strategies.
A fintech company I know spent $50,000 in their first month using GPT-4 for customer support because they didn’t implement prompt caching or output length limits. After optimization—using GPT-3.5 for simple queries, caching common responses, and limiting output tokens—they cut costs by 70% without noticeable quality degradation.
Performance evaluation is trickier than traditional ML. Standard metrics like accuracy don’t capture text quality. LLMOps uses specialized metrics like BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation), plus human evaluation frameworks.
But even these metrics have limits. BLEU scores can be high for text that’s technically correct but useless to users. You need human evaluators to assess whether responses actually solve customer problems, which is expensive and slow to scale.
When to Use LLMOps
LLMOps fits language-centric applications:
- Conversational AI and chatbots for customer support or virtual assistants
- Content generation systems for marketing, documentation, or creative writing
- Document summarization and analysis for legal, medical, or research applications
- Code generation and assistance for developer tools
- Translation and localization services
- Sentiment analysis and text classification at scale
These applications leverage the general language understanding of foundation models, usually with task-specific fine-tuning or prompt engineering.
AgentOps: The Next Frontier
Autonomous agents are a different beast. Unlike static models that just respond to inputs, agents can plan, make decisions, use tools, and execute multi-step workflows with minimal human intervention. This autonomy creates new operational challenges.
Understanding Autonomous Agents
An AI agent isn’t just a model—it’s a system that perceives its environment, makes decisions based on goals, and takes actions to achieve those goals. A customer support agent might monitor incoming emails, search a knowledge base, create support tickets, and escalate issues to human operators—all on its own.
This complexity creates multiple failure points. Did the agent retrieve the correct documentation? Which APIs did it call and in what order? How long did each step take? What was the total cost? Traditional monitoring tools don’t give you this visibility.
Here’s a real example: imagine an agent handling insurance claims. It needs to read the claim, extract relevant information, check policy details, verify coverage, calculate payouts, and generate approval documents. If it misreads a policy number in step two, the entire downstream process fails—but in ways that might not be obvious until a customer complains. You need to trace the entire decision chain to understand what went wrong.
Core Principles of AgentOps
End-to-end observability is essential. Every stage of agent execution needs to be traceable: what data the agent received, how it reasoned about the problem, and which systems it engaged with. Event logging captures each action with timestamps and context. Real-time dashboards show response times, accuracy, and error rates. Anomaly detection systems catch unexpected behavior patterns.
Traceable artifacts ensure accountability. Decision logs document why an agent took specific actions. Version control tracks changes to agent code, configurations, and prompts. Reproducibility mechanisms let developers replay agent sessions exactly—critical for debugging and compliance, especially in regulated industries like healthcare and finance.
Advanced monitoring and debugging tackles the unique challenges of agentic systems. RAG pipeline monitoring ensures agents retrieve accurate information from knowledge bases. Prompt engineering tools enable iterative refinement of agent instructions. Workflow debuggers visualize multi-step processes, showing inputs and outputs at each stage. Error attribution helps identify whether failures come from the agent’s reasoning, external APIs, or data quality issues.
The AgentOps Lifecycle
The design phase defines agent objectives, maps workflows, and engineers initial prompts. Teams need to carefully consider what autonomy to grant and what constraints to impose.
The development phase integrates LLMs, builds specialized modules, and tests in simulated environments. Sandbox testing lets developers observe agent behavior without real-world consequences.
The deployment phase introduces agents to production with monitoring pipelines, error handling, and feedback loops. Gradual rollouts and human-in-the-loop oversight help manage risk.
The maintenance phase keeps agents effective through knowledge base updates, performance audits, and behavior refinement based on observed outcomes.
When to Use AgentOps
AgentOps fits systems that need autonomous decision-making and multi-step workflows:
- Intelligent customer service systems that handle complex inquiries across multiple systems
- Process automation in insurance claims, loan processing, or HR workflows
- Intelligent tutoring systems that adapt to individual learning styles
- Supply chain optimization with dynamic decision-making
- Research assistants that can search, synthesize, and present information
- DevOps automation for incident response and system management
The differentiator is autonomy. Agents don’t just respond to inputs—they pursue goals through multi-step reasoning and action.
Comparison: Choosing the Right Framework
Here’s how these frameworks differ and when to use each one.
The choice between MLOps, LLMOps, and AgentOps isn’t always clear-cut. Many production systems use multiple frameworks simultaneously. A recommendation system might use MLOps for the core ranking model, LLMOps for generating product descriptions, and AgentOps for a shopping assistant that helps users find products through conversation.
Scope and Complexity
MLOps manages individual models with defined inputs and outputs. The focus is on model performance, data quality, and deployment reliability.
LLMOps extends this to large language models, adding prompt engineering, token cost management, and content moderation. The model itself is often a black box (especially with proprietary models), so the focus shifts to input/output optimization.
AgentOps manages entire autonomous systems that make decisions, use tools, and execute workflows. The scope expands from model management to behavior governance.
Cost Structures
MLOps costs center on training infrastructure, data storage, and inference compute. Costs are relatively predictable and scale with usage.
LLMOps shifts costs to inference, with token-based pricing making every interaction a line item. Prompt length, output constraints, and model selection directly impact expenses.
AgentOps adds to LLM costs with expenses for tool usage, API calls, and extended reasoning chains. Cost optimization means understanding entire workflow economics.
Monitoring Focus
MLOps monitors model performance metrics like accuracy, precision, recall, and latency. Data drift detection signals when retraining is needed.
LLMOps adds prompt effectiveness, hallucination rates, content safety, and token efficiency. Human evaluation often supplements automated metrics.
AgentOps monitors decision-making processes, tool usage patterns, workflow completion rates, and behavioral anomalies. Session replay and trajectory analysis are essential.
Governance and Compliance
MLOps focuses on model versioning, data lineage, and performance documentation. Compliance centers on data privacy and model fairness.
LLMOps adds content moderation, bias detection, and output filtering. Regulatory concerns include copyright, misinformation, and ethical AI use.
AgentOps needs comprehensive audit trails of agent decisions and actions. Governance frameworks must address autonomy boundaries, safety constraints, and accountability mechanisms.
Implementation Strategies
Implementing these frameworks takes planning. Here’s what works.
Start with Strong Foundations
Establish MLOps practices before moving to LLMOps or AgentOps. Core capabilities like version control, automated testing, monitoring infrastructure, and CI/CD pipelines provide the foundation for more advanced frameworks.
Adopt Incrementally
Don’t try to implement all three frameworks at once. Start with MLOps for traditional models, expand to LLMOps as you add language models, and move to AgentOps only when you need autonomous agent capabilities.
Invest in Observability
Visibility into system behavior matters at every level. Implement comprehensive logging, monitoring dashboards, and alerting systems. For agents, invest in session replay and trajectory analysis tools.
Build Feedback Loops
Human feedback is essential for LLMs and agents. Create mechanisms for users and operators to flag issues, rate outputs, and provide corrective guidance. Use this feedback to continuously improve system performance.
Prioritize Safety and Ethics
As systems become more autonomous, safety and ethics become more important. Establish clear guidelines, implement guardrails, and maintain human oversight for high-stakes decisions.
Consider Hybrid Approaches
Many organizations succeed with unified platforms that support multiple operational frameworks. Tools like Dataiku integrate MLOps, LLMOps, and AgentOps capabilities, reducing fragmentation and improving collaboration.
The Future of AI Operations
The operational landscape keeps evolving. Here are the trends shaping what comes next:
Self-observing agents that can monitor and optimize their own behavior are starting to appear. These meta-cognitive capabilities could reduce operational overhead while improving performance. Imagine an agent that notices its response times are slow, identifies the bottleneck (maybe it’s making too many API calls), and automatically adjusts its workflow to be more efficient.
Standardized protocols are developing across the industry. OpenTelemetry standards for agent instrumentation, common metrics frameworks, and shared best practices will make AgentOps more accessible. Right now, every team is inventing their own monitoring and observability solutions. Standardization will help, but we’re still in the early days.
Inter-agent collaboration frameworks will let multiple agents work together on complex tasks. This creates new challenges in coordination, communication, and conflict resolution. What happens when two agents disagree about the best course of action? How do you prevent agents from duplicating work or creating conflicting outputs?
Federated learning approaches let you train models across distributed data sources without centralizing sensitive information. This addresses privacy concerns while leveraging larger datasets. Healthcare organizations, for example, could collaboratively train models on patient data without ever sharing the actual patient records.
Edge deployment brings AI operations closer to end users, cutting latency and bandwidth costs. This matters for real-time applications and IoT scenarios. Manufacturing plants are deploying agents directly on factory floors to make split-second decisions about production line adjustments without waiting for cloud round-trips.
Conclusion
The shift from MLOps to LLMOps to AgentOps tracks how AI systems have become more sophisticated. Each framework tackles different challenges and use cases.
MLOps handles traditional machine learning: model lifecycle management and deployment reliability. LLMOps extends these practices for large language models, adding prompt engineering, token cost optimization, and content safety. AgentOps is built for autonomous agents that can reason, decide, and act independently.
These frameworks aren’t competing alternatives—they’re complementary tools. Start with MLOps foundations, expand to LLMOps when you add language models, and adopt AgentOps when you need autonomous capabilities.
As AI systems evolve, the operational practices will evolve with them. Success means building systems that are observable and governable, that can adapt to new requirements while staying reliable and safe. You’ll likely need all three frameworks eventually. The question is knowing which one fits your current problem.


